
BY Dash Team
Agent Security
11 MIN READ

A compromised README tells a developer's AI coding agent to run a setup command. The agent trusts the documentation, executes the script, and exfiltrates AWS credentials cached on the endpoint. Minutes later, a new IAM principal is provisioning resources in the customer's cloud. EDR sees a shell command from a trusted developer process. CloudTrail sees API calls from a familiar IP. Neither tool sees that a markdown file caused the breach.
This is the threat model security teams are now working against. Workstation AI agents, coding agents like Cursor and personal productivity agents like Claude Cowork, run on user endpoints with user privileges. They interpret instructions, pull context from local, enterprise, and web sources, call tools, and take actions across applications and data on the user's behalf. The result is a system whose behavior is shaped by inputs that traditional security tools treat as data, not control flow.
This blog breaks down the workstation agent attack surface, the concepts defenders need to understand, the ways risky behavior can be introduced or amplified, and the methodology for mapping agent impact across endpoints, SaaS, code, cloud systems, and business workflows. The goal is to help security teams move from generic AI concerns to a practical threat model they can use to reduce agentic risk before it turns into enterprise impact.
Why agent threat modeling is different
First they do not just execute fixed workflows. Their behavior changes based on prompts, context, memory, tool outputs, and session state, and they can read from one system and act in another.
Second, agents mix content, instructions, and supply chain influence. A README, email, webpage, ticket, tool response, plugin, MCP server, skill, hook, model, or connector can all influence behavior. What looks like data to process can become instructions the agent follows.
Third, agents act with delegated authority. They may use the user’s identity, browser sessions, local credentials, OAuth grants, API tokens, cloud roles, or tool-held secrets. That makes blast radius dynamic and highly dependent on what the agent can actually access or change.
Fourth, existing tools see fragments, not the causal chain. EDR may see a shell command from a trusted IDE, DLP sees an outbound request, CloudTrail logs an API call from a valid developer key, CSPM sees a new IAM role created, SIEM stitches the logs together but has no signal that ties them to the same agent decision. What they often miss as a connected view, is what influenced the agent, what authority it used, what action it took, and where the impact landed.
Key Concepts for Defenders
Concept | Definition | Why it matters for defense |
Cause of risky behavior | The input, component, condition, or actor that can cause or influence the agent to behave in a risky, unauthorized, or unintended way. | Helps identify trusted and untrusted sources of influence that can enter the agentic flow, so teams can decide what should be monitored, validated, constrained, or blocked. |
Exploited attack surface | The attack surface component that has a condition which when exploited allows for the cause to influence agent behavior | Helps identify the conditions in the agentic footprint that can be remediated to harden the attack surface and reduce the likelihood of risky agent behavior |
Blast radius | The systems, data, workflows, users, or business processes that could be impacted if the agent takes risky, unintended, or malicious action. | Helps map what could be impacted, how severe that impact could be, and where monitoring, guardrails, and response controls may be needed. |
Risk amplifiers | A high leverage condition or control surface that can amplify the likelihood, speed, scope, impact, or detection difficulty of agentic risk across different attack paths. E.g. Identities | Helps defenders prioritize which controls will have the biggest impact in reducing risk |
The Attack Surface
The attack surface is broken down into five categories, each defined below along with the role it plays in realization of risk
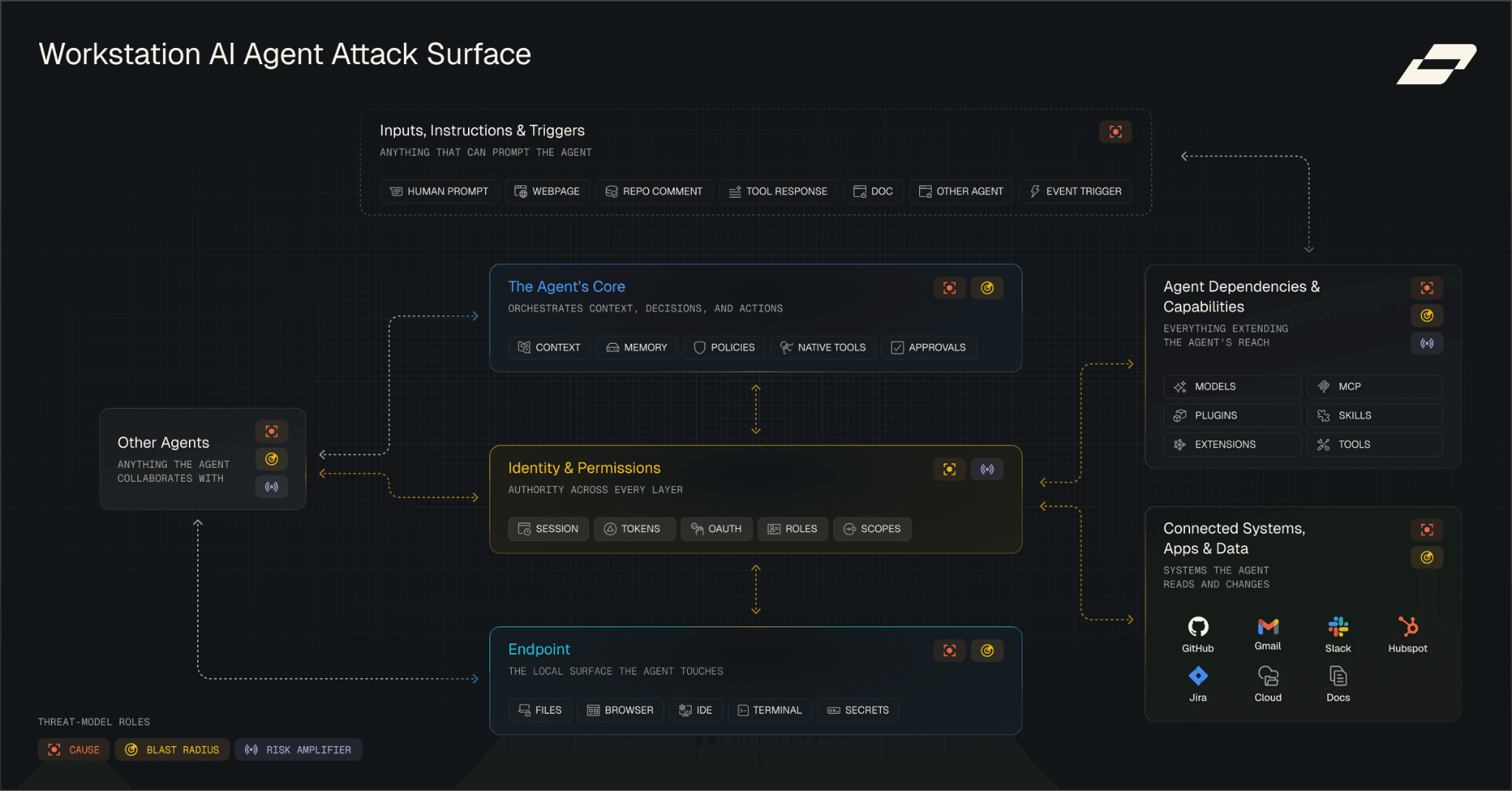
Figure 1: Workstation AI Agent Attack Surface
The Agent’s Core
The agent’s native orchestration layer. It assembles context, applies instructions and policies, manages session state and memory, invokes the model, interprets model outputs, routes actions, uses native capabilities, coordinates approvals, and manages native subagents. The model itself is treated as part of the agent dependency layer.
In the threat model, the agent’s core is usually not the cause. The cause is more often a prompt, file, email, webpage, repo rule, skill, tool response, or plugin instruction. The core becomes the exploited attack surface when it fails to separate trusted instructions from untrusted content, and routes sensitive actions without validation
Endpoint Execution Environment
The local machine where the agent runs. Examples include local files, browser sessions, IDE, terminal, clipboard, downloads, local secrets, SSH keys, cached credentials, and other local agent processes.
The endpoint can be an exploited attack surface and introduce the cause of risky influence through local content, browser state, files, or other local agents. It can also be part of the blast radius when the agent modifies files, exposes secrets, changes configuration, or runs unsafe commands.
Agent Dependencies and Capabilities
The supply chain that powers, extends, connects, configures, or triggers the agent. Examples include foundation models, open-source models, model gateways, MCP servers, tools, skills, plugins, extensions, SaaS connectors, API wrappers, hooks, webhooks, automations, and external worker agents.
Dependencies and capabilities can introduce the cause of risky influence through malicious tool descriptions, compromised MCP servers, poisoned plugin behavior, unsafe hooks or malicious skills. They become an exploited attack surface when the agent trusts these components without validating what they are asking it to do or what they actually execute. They can also amplify risk by expanding the agent’s reach across APIs, SaaS apps, cloud resources, code repositories, and automation paths. In some cases, they become part of the blast radius when they leak data, mutate systems, or create persistence outside the endpoint.
Connected Apps, Systems & Data
The applications, systems, workflows, and data sources the agent can read from, write to, act on, or be influenced by. Examples include GitHub, CI/CD, Gmail, Calendar, Slack, HubSpot, Jira, Google Drive, cloud resources, documents, customer records, public websites, and knowledge bases.
Connected systems can introduce the cause of risky influence through emails, tickets, repo comments, documents, public webpages etc that the agent reads as context. They can also become part of the blast radius when the agent updates CRM records, changes tickets, commits code, modifies cloud resources, exposes documents, or triggers CI/CD workflows. This category is especially important because the source of influence and the destination of impact often live in different systems, with the workstation agent acting as the bridge.
Identity & Permissions
The authority layer the agent uses to access or change systems and data. This includes user identity, agent identity, sessions, tokens, OAuth grants, roles, scopes, repo permissions, SaaS permissions, cloud permissions, and tool held credentials.
Identity and permissions can introduce risk when credentials, sessions, grants, or roles are compromised, over-scoped, misused, or silently inherited by the agent. They become a risk amplifier when broad OAuth grants, local cloud keys, repo write access, SaaS admin permissions, persistent tokens, or tool held credentials allow the same risky agent behavior to have much wider impact. They define blast radius by determining what the agent can actually read, modify, delete, exfiltrate, deploy, or persist into when influenced into taking the wrong action.
Attack Scenarios
The scenarios below are a combination of what we have detected through our customer deployments and what has been reported in the wild. Each is mapped to a cause of the risky behavior, how the attack unfolds, its blast radius and impact and visibility of the kill chain across existing security tools.
Scenario | Impact and Blast Radius | How existing tools see it |
Poisoned dependency README. A compromised README tells the agent to run a setup command. The agent trusts the documentation and executes a script that steals AWS credentials. | Cloud compromise through legitimate developer credentials. The workstation is the starting point, but the damage lands in AWS. | EDR sees a normal shell or curl command from a trusted agent entity. Cloud IAM logs may later see AWS activity from a new IP. No tool sees that the README caused the agent action. |
Repo session file backdoors code. A | Production code contains exfiltration behavior that fires after deployment. | EDR sees normal file writes. Git sees a legitimate developer commit. Static analysis may miss it because it looks like normal instrumentation. |
Malicious MCP server mutates cloud config. An MCP advertised as an AWS cost analyzer includes injected tool instructions that create attacker controlled cloud resources. | Cloud persistence, data leakage, and unauthorized IAM or resource changes under developer credentials. | CNAPP / IAM may see unusual API calls. EDR is blind. No tool sees that the agent was steered by tool metadata. |
Committed hook creates persistence. A repo includes a hooks file that runs during normal agent activity, injects instructions, and writes persistence such as SSH keys or shell config. | Endpoint and remote persistence that survives the agent session. Possible SSH or cloud access. | EDR may see file writes but attribute them to trusted developer tooling. The agent-context injection is invisible. |
Approach to Threat Modeling Agents
Start by mapping the agentic workflow, not just the assets. Identify what the agent can read, what can influence it, what tools it can call, what systems it can modify, and what credentials it can exercise. For each workflow, ask five questions.
What can influence the agent? Map all components, inputs and triggers that directly influence or facilitate risky behavior
What control surface could be exploited? Identify the weaknesses the risky influence can exploit. These conditions usually fall into a few categories: vulnerabilities in the agent, misconfigurations in tools or permissions, unsafe defaults, weak trust boundaries, poor approval controls, over trusted inputs, risky extensions, and gaps in validation or monitoring. The goal is to find the conditions that let a prompt, file, email, repo rule, plugin, MCP server, or tool response move from “untrusted input” to “agent action.”
What authority can the agent exercise? Map the identity and permissions available to the agent. This includes user identity, agent identity, browser sessions, OAuth grants, API keys, local credentials, cloud roles, repo permissions, SaaS scopes, SSH keys, and tool held credentials. The goal is to understand the agent’s effective authority: what it can actually read, modify, delete, share, deploy, or persist into.
Where can the action land? Map the systems the agent can reach, then map what it can do in each system. Start with reachable destinations: endpoint, files, browser, IDE, GitHub, CI/CD, SaaS apps, cloud, documents, tickets, CRM, and production workflows. Then layer on permissions: read, write, delete, commit, deploy, share, create credentials, or change configuration. That combination defines the blast radius.
What would existing tools actually see? Map out what existing security solutions like EDR, CNAPP, CASB, SIEM, DLP, see against the full agentic action path. They may be fully or partially blind, seeing only a process, API call, file change, SaaS update, package, or data movement. That partial view can miss the attack, create low confidence alerts, or block one action without revealing what influenced the agent, what condition was exploited, what path the action took, and where the same risky influence may still exist.
The output should be a prioritized action plan: constrain permissions, isolate and inspect untrusted context and supply chain components, validate tools, monitor full agent sessions, gate sensitive actions, require meaningful approvals, detect risky tool chains, and preserve full agentic audit trails.
Key Takeaways
Agent threat modeling is different. Workstation agents are non-deterministic and do not follow fixed app workflows. They interpret instructions, mix trusted and untrusted context, use tools, act with delegated authority, and move across endpoint, SaaS, code, cloud, and business systems.
Defenders need to map attack surfaces by the role they play. Each surface should be analyzed for whether it introduces the cause of risky behavior, becomes the exploited attack surface, expands the blast radius, or acts as a risk amplifier.
The output of threat modeling should be actionable. Map what can influence the agent, what conditions can be exploited, where actions can land, what authority the agent can use, and what existing tools miss. Then use that to prioritize controls: reduce permissions, constrain tools, isolate untrusted context, strengthen approvals, monitor agent sessions, and close visibility gaps.
Continue reading



Switch to